Teradata Group By clause makes the group of related rows. The group by clause identifies the rows which have the same value for the specified attribute (i.e, duplicate value) and returns a single row of information instead of all the rows where the attribute has the same value.
This can be done by specifying one or more columns in a table as grouping column(s).
Teradata GROUP BY syntax
The syntax of the Teradata GROUP BY clause is as below.
Select column_name from DatabaseName.TableName Group By column_name;
With Aggregate Function
Select column_name , sum(column_2) from DatabaseName.TableName Group By column_name;
Please note that column_name can be used with the aggregate function only if it appears in the GROUP BY clause.
Teradata GROUP BY clause example
Consider the following employee table.
| emp_id | emp_name | emp_phone | emp_gender | department |
| 101 | Kalyan Roy | 9620139678 | M | HR |
| 102 | Rajesh Sharma | 9611895588 | M | ADMIN |
| 103 | Rupali Sharma | 8884692570 | F | SALES |
| 104 | Dipankar Sen | 9957889640 | M | HR |
| 105 | Sunitha Rai | 9742067708 | F | SALES |
| 106 | Parag Barman | 8254066054 | M | MARKETING |
| 107 | Vinitha Sharma | 9435746645 | F | ADMIN |
| 108 | Abhishek Saha | 9850157207 | M | SALES |
| 109 | Rushang Desai | 9850157207 | M | SALES |
| 110 | Arvin Kumar | 8892340054 | M | ADMIN |
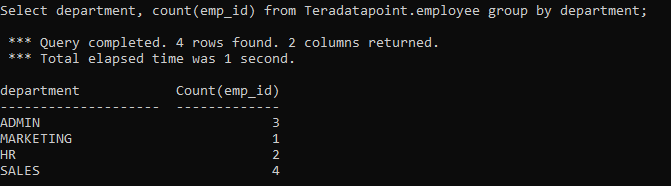
The below query finds the numbers of employees in the different departments.
Select department, count(emp_id) from Teradatapoint.employee group by department;
Output:
1 thought on “Teradata GROUP BY Clause”